
BUGCLASSIFY
It’s not a Bug, it’s a Feature: On the Data Quality of Bug Databases
Universität des Saarlandes – Informatik
Informatik Campus des Saarlandes
Campus E9 1 (CISPA)
66123 Saarbrücken
E-mail: zeller @ cs.uni-saarland.de
Telefon: +49 681 302-70970



The Software Evolution project at the Software Engineering Chair, Saarland University, analyzes version and bug databases to predict failure-prone modules, related changes, and future development activities.
It’s not a Bug, it’s a Feature: On the Data Quality of Bug Databases
In a manual examination of more than 7,000 issue reports from the bug databases of five open-source projects, we found 33.8% of all issue reports to be misclassified, that is, rather than referring to a code fix, they resulted in a new feature, an update to documentation, or an internal refactoring. This misclassification introduces bias in bug prediction models, confusing bugs and features: On average, 39% of files marked as defective actually never had a bug. We estimate the impact of this misclassification on earlier studies and recommend manual data validation for future studies.The Paper
The paper describing the issue of misclassified issue reports and their impact on data mining models is currently under submission for ICSE 2013.Technical Report
You can download a technical report version of the paper here.BibTex
@techreport{herzig-tr-2012,
title = "It's not a Bug, it's a Feature: How Misclassification Impacts Bug Prediction",
author = "Kim Herzig and Sascha Just and Andreas Zeller",
year = "2012",
month = "August",
institution = "Universität des Saarlandes, Saarbrücken, Germany",
}
About this Website
We strongly recommend reading our paper. This will be required to understand our findings, experimental setup and the correct use of the public available data sets. The purpose of this website is to present additional results that did not fit in our papers and to make the used data sets public available for future research. The raw data sets can be downloaded from the download section. When using our data sets, please make sure to include our paper in your references.What is this all about and why should I care?
Bug tracker and their content are frequently used to measure or estimate the reliability and quality of software systems. Mapping bug reports to code changes and thus to individual files allows to count the number of fixes applied to individual files in the past. Files being frequently fixed are considered to be fragile and of lower quality than files that have not been fixed. The underlying assumption is that bug reports refer to corrective maintenance tasks. We conducted a manual inspection of more than 7,000 issue reports and found 33% of all issue reports (not only bug reports) to be misclassified—that is, rather than referring to a code fix, they resulted in a new feature, an update to documentation, or an internal refactoring. Such misclassifications introduce bias in bug prediction models treating misclassified feature requests as bugs and vice versa. On average every third bug is no bug and around 40% of files marked as defective actually never had a bug.How can I check if my studies/approaches are affected?
In general, empirical studies that use or used bug data sets without performing explicit purity checks are threatened to be biased. If you ensure/ensured (e.g. using test cases, heuristics on project history, or report classification models) to count only bug reports that indeed refer to corrective maintenance tasks your study is likely to be be unaffected. Many empirical studies reuse approaches first introduced by Fischer et al. [3] and Cubranic et al. [4] that described procedures to created a release history database from version control and bug tracking systems and to map bug reports to code changes. Although these studies are not biased themselves, any study using these or similar bug data sets without performing extra bug type purity checks rely on the original data mining processes that do not check for bug type misclassifications.[3] M. Fischer, M. Pinzger, and H. Gall, "Populating a release history database from version control and bug tracking systems", in Proceedings of the International Conference on Software Maintenance, ser. ICSM’03. IEEE Computer Society, 2003, pp. 23–32.
[4] D. Cubranic, G. C. Murphy, J. Singer, and K. S. Booth, "Hipikat: A project memory for software development", IEEE Trans. Softw. Eng., vol. 31, no. 6, pp. 446–465, Jun. 2005.
Additional Results
Average Report Type distibutions
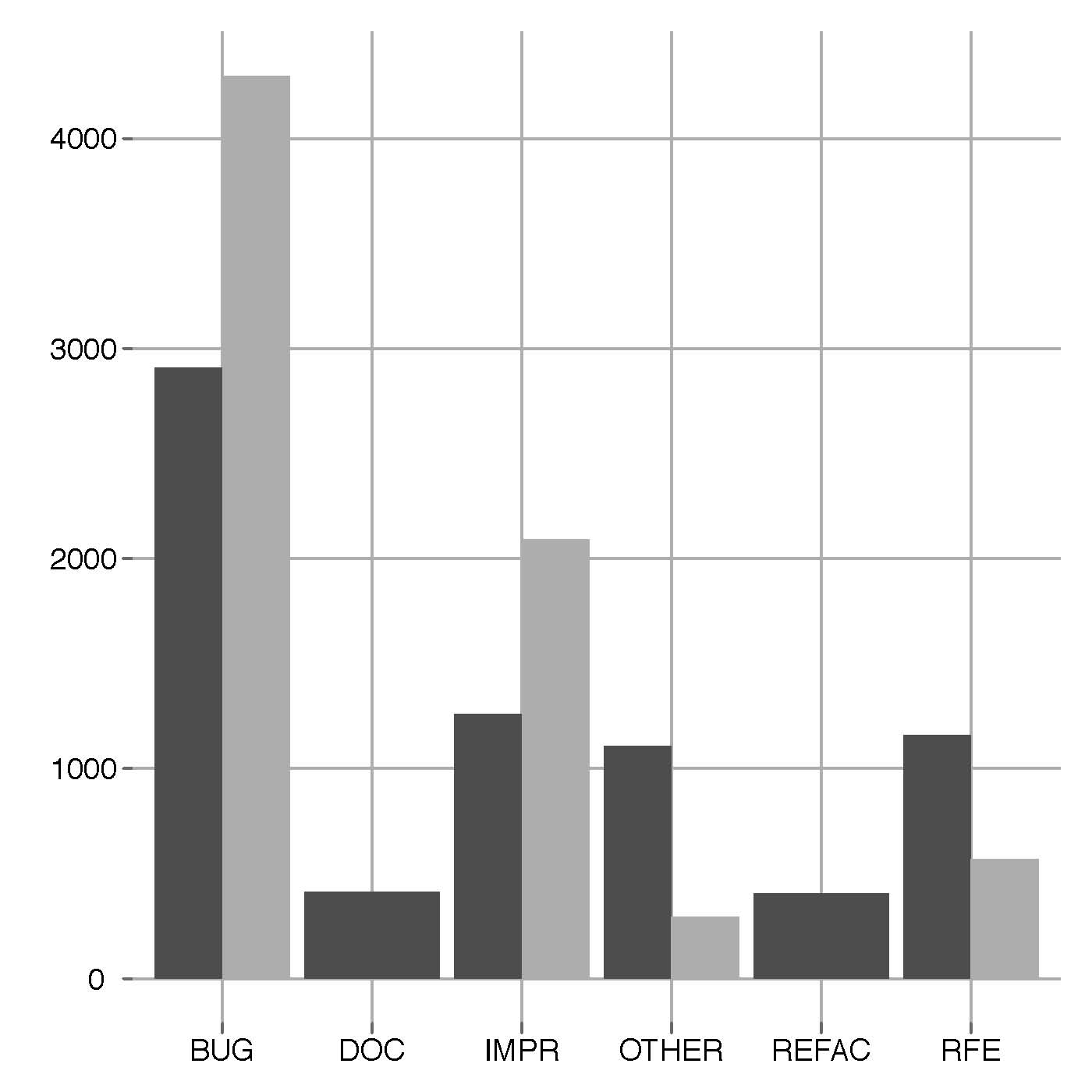
Dark gray bars refer to Jira bug tracking systems (Lucene-Java, Jackrabbit, HTTPClient). Light gray bars represent projects using Bugzilla bug trackers (Rhino, Tomcat).
Additional Noise Slices
coming soon
DiffNumBagRates as Bar Plots
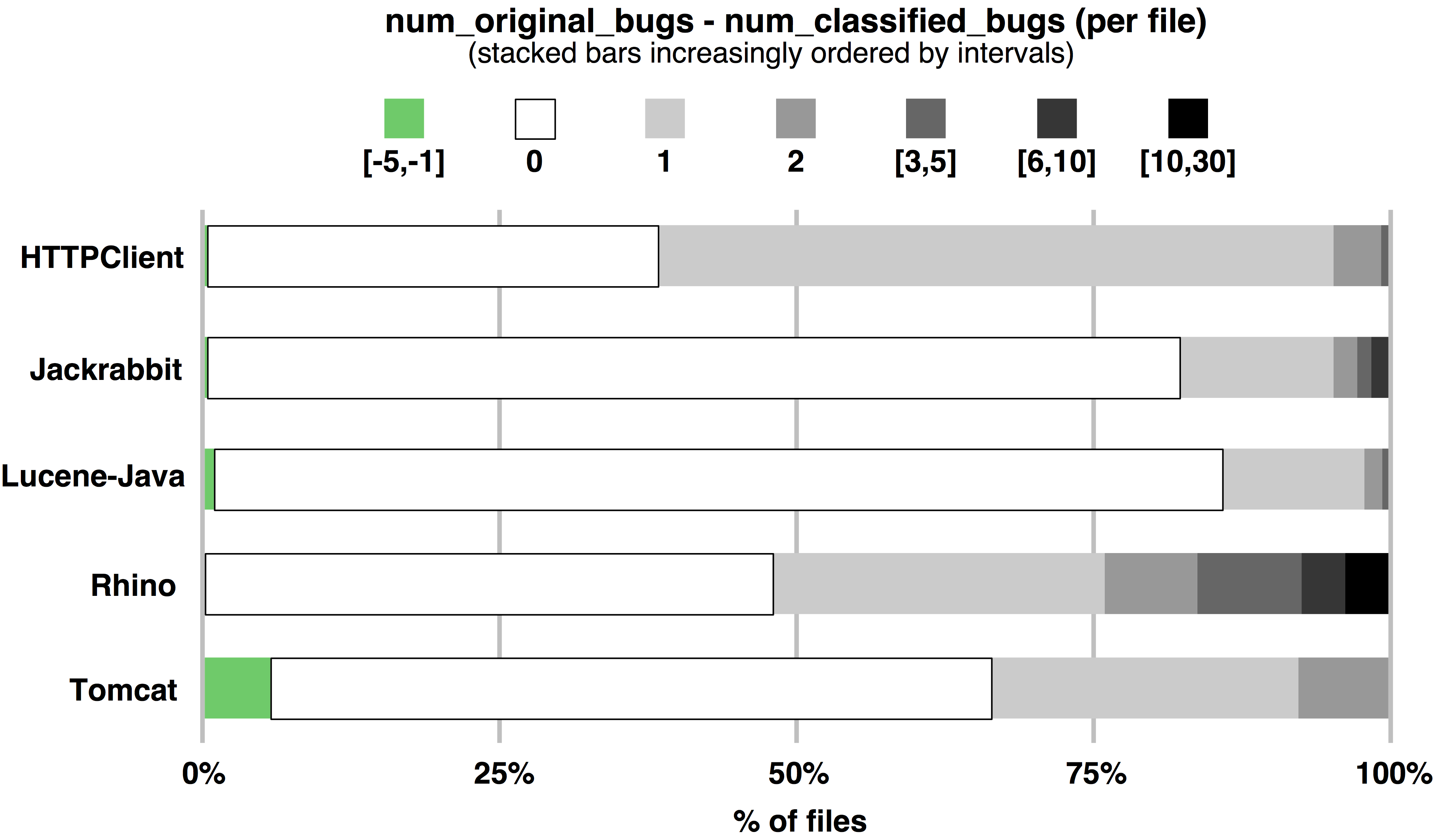
Due to space reasons, Figure 3 in our paper appears small and makes it hard to estimate the number of files for which more defects could be found (please click on the plot to further increase).
To further increase the readability we provide an extra bar plot that corresponds to the stacked bar plots presented in Figure 3 in our paper.
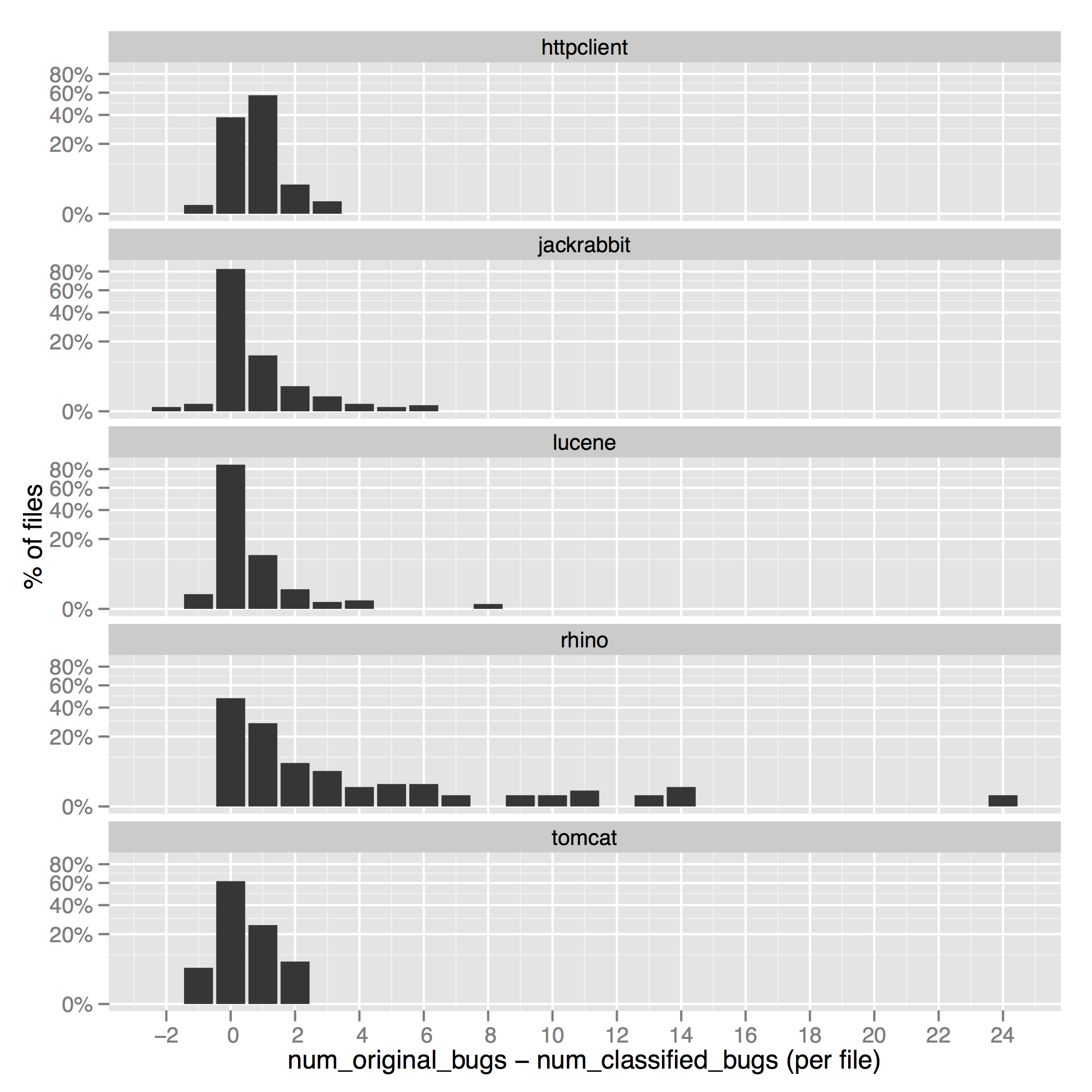
Spearman Rank Correlations as Plot
This plot visualizes the spearman rank correlations presented in Table X our paper.
Download Data Sets
- Download HTTPClient classification CSV
- Download Jackrabbit classification CSV
- Download Lucene classification CSV
- Download Rhino classification CSV
- Download Tomcat5 classification CSV
Feedback and Comments Welcome
Any feedback, comments, and suggestions are welcome. Please contact us using the email address:bugclassify (at) st (dot) cs (dot) uni-saarland (dot) de.
Impressum ● Datenschutzerklärung
<webmaster@st.cs.uni-saarland.de> · http://www.st.cs.uni-saarland.de/softevo/bugclassify/?lang=de · Stand: 2018-04-05 13:41